
O laboratório chinês de inteligência artificial DeepSeek disse ter reduzido muito os recursos de computação e de memória necessários para inferência de tokens com seu novo modelo V4, segundo as notas de lançamento.
A empresa diz que o V4 usa apenas 27% dos FLOPs por token e 10% do cache de chave-valor (KV) em comparação com o modelo anterior, o DeepSeek V3.2. A redução no uso de cache diminui a demanda por memória e aumenta o contexto disponível para quem cria modelos.
Como o DeepSeek V4 reduz custo de computação e memória
Nas notas de lançamento do DeepSeek V4, a empresa informa que o modelo usa 27% dos FLOPs por token e 10% do cache KV ao operar com uma janela de contexto de um milhão de tokens.
A janela de contexto é a quantidade de texto que um modelo de linguagem consegue processar antes de liberar memória.
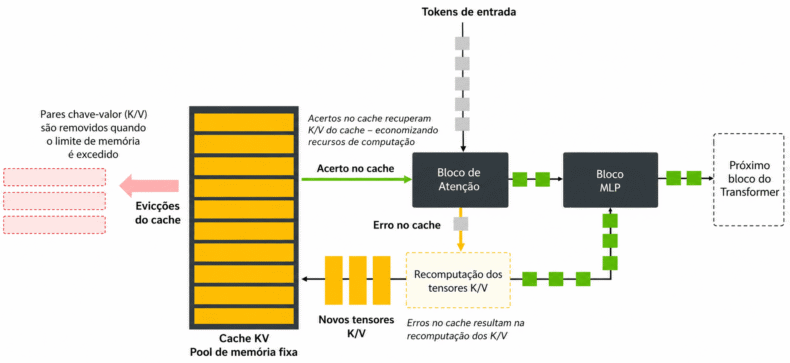
Esse melhor uso da memória é importante na fase chamada de Decode. O processamento em IA costuma ser dividido em duas etapas: Prefill e Decode.
Como o modelo gera respostas na fase Decode, ele precisa guardar o contexto da conversa ou do comando recebido na etapa Prefill. Por isso, a fase Decode exige mais memória, principalmente por causa do cache KV.
O ponto de equilíbrio: compressão e risco de falhas
À medida que o número de tokens aumenta, também cresce a necessidade de cache KV. Em um cenário com um milhão de tokens, um modelo que usa menos cache consegue atender mais pedidos ou precisa de menos memória.
A outra afirmação da DeepSeek, de usar 27% dos FLOPs por token, só traz ganho se houver memória suficiente na GPU para os cálculos.
Além disso, reduzir muito o uso de cache exige ajustes que podem fazer o modelo perder detalhes. Esse tipo de problema é conhecido como "agulha no palheiro" e pode gerar respostas menos precisas.
Impacto no hardware: pressão menor sobre a memória
Esse avanço tem impacto direto no hardware. Reduzir o uso de cache KV não é só uma mudança de software, mas também afeta a cadeia de fornecimento de memória.
O setor vive um ciclo de alta na DRAM, puxado pela grande demanda por HBM. Isso tem causado falta de oferta e aumento de custo, afetando peças como memória RAM e SSDs usados em PCs.
Técnicas de compressão como as do DeepSeek V4, junto com mudanças em algoritmos como o TurboQuant do Google, podem ajudar a diminuir essa pressão no hardware.
Isso quer dizer que, se os modelos conseguirem gerar mais resultados usando menos memória, o custo tende a cair para o consumidor final, que hoje sente o impacto do uso crescente de memória em IA.
Como funciona: mecanismo Multi-Head Latent Attention
O ganho de eficiência vem da arquitetura chamada Multi-Head Latent Attention (MLA), já usada em modelos anteriores da empresa. Esse design foi pensado desde o início para lidar com limites de memória.
Em vez de armazenar todos os dados de chave e valor para cada token, o MLA transforma essas informações em uma representação menor e compartilhada. Depois, esses dados são expandidos novamente no momento do cálculo.
Esse processo de comprimir e expandir reduz bastante o uso de cache KV, permitindo que o modelo funcione com menos memória do que métodos tradicionais.







