
A NVIDIA avalia caminhos para ampliar sua presença no mercado de inferência com a próxima geração de GPUs Feynman. A ideia em estudo envolve a integração de unidades LPU, tecnologia associada à Groq, dentro da própria arquitetura dos chips, com previsão de adoção por volta de 2028.
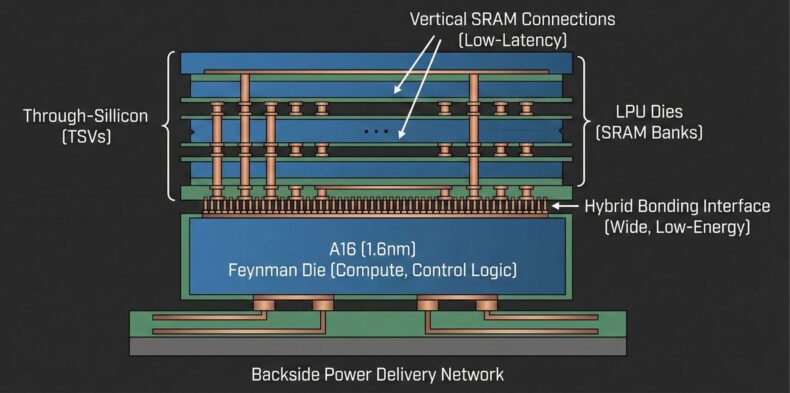
Segundo análises atribuídas ao especialista em GPUs conhecido como AGF, a empresa pode usar a tecnologia de hybrid bonding da TSMC para empilhar esses blocos de LPU diretamente sobre o chip principal das GPUs Feynman.
A proposta lembra a estratégia usada pela AMD em processadores com X3D, que adotam o SoIC da TSMC para unir o die principal a camadas adicionais de cache 3D V-Cache. De acordo com essa visão, integrar grandes blocos de SRAM em um único die não seria a melhor escolha para a NVIDIA.
A escalabilidade desse tipo de memória é limitada, e sua fabricação em nós avançados tende a consumir silício de alto custo de forma pouco eficiente, elevando o preço por área de wafer.
Como alternativa, a solução apontada envolve empilhar dies dedicados às LPUs, responsáveis por grandes bancos de SRAM, sobre o die principal de computação das GPUs Feynman.
Nesse cenário, o chip central seria produzido em um processo avançado como o A16 de 1,6 nanômetro, concentrando unidades de cálculo, como blocos tensores e lógica de controle. Já os dies de LPU ficariam encarregados do armazenamento em SRAM.
A interligação entre essas partes dependeria do hybrid bonding da TSMC, que garante uma interface ampla e consumo de energia por bit menor em comparação com memórias fora do encapsulamento.
Groq LPU blocks will first appears in 2028 in Feynman (the post Rubin generation).
Deterministic, compiler-driven dataflow with static low-latency scheduling and Higher Model Floats Utilization (MFU) in low-batch scenarios will give Feynman immense inference performance boost in… https://t.co/GVZCWiENC2— AGF (@XpeaGPU) December 28, 2025
O uso de alimentação traseira no processo A16 também liberaria a parte frontal do chip para conexões verticais de SRAM, o que ajudaria a manter baixa latência em operações de decodificação.
Apesar das vantagens teóricas, essa abordagem traz desafios técnicos relevantes. O empilhamento de dies em um chip com alta densidade de cálculo amplia a complexidade térmica, já que a dissipação de calor se torna mais difícil.
A presença de LPUs voltadas a fluxo contínuo de dados também pode gerar gargalos em certos cenários de uso. Há ainda implicações no nível de execução.
As LPUs costumam trabalhar com ordens de execução fixas, o que cria tensão entre previsibilidade e flexibilidade. Isso se torna um ponto sensível quando se considera o ecossistema CUDA, que foi projetado para abstrair detalhes de hardware.
Em modelos de execução mais próximos do estilo LPU, é necessário controle explícito da alocação de memória, algo que não faz parte do comportamento tradicional dos kernels CUDA.

Mesmo que a NVIDIA consiga superar os limites físicos do hardware, o maior obstáculo tende a estar na integração entre GPU e LPU em nível de software.
Ajustar o uso de SRAM dentro de arquiteturas de IA exige um alto grau de engenharia para manter o ambiente bem ajustado. Ainda assim, essa pode ser a aposta da empresa para assumir uma posição de liderança no segmento de inferência.







