
Apesar das enormes contribuições do aprendizado profundo para o campo da inteligência artificial, há algo muito errado com isso, ela requer grandes quantidades de dados.
Essa é uma coisa em que tanto os pioneiros quanto os críticos do aprendizado profundo concordam, o aprendizado profundo não emergiu como a principal técnica de IA até alguns anos atrás, devido à disponibilidade limitada de dados úteis e à escassez de poder computacional para processar esses dados.
Reduzir a dependência de dados da aprendizagem profunda está atualmente entre as principais prioridades dos pesquisadores de IA.
Em seu discurso na conferência da AAAI, o cientista da computação Yann LeCun discutiu os limites das técnicas atuais de aprendizado profundo e apresentou o plano para o "aprendizado auto supervisionado", seu roteiro para resolver o problema de dados do aprendizado profundo.
LeCun é um dos padrinhos do aprendizado profundo e o inventor das redes neurais convolucionais (CNN), um dos elementos-chave que provocaram uma revolução na inteligência artificial na última década.
O aprendizado auto supervisionado é um dos vários planos para criar sistemas de inteligência artificial com eficiência de dados;
Nesse ponto, é realmente difícil prever qual técnica será bem-sucedida na criação da próxima revolução da IA ou se será necessário adotar uma estratégia totalmente diferente.
Um esclarecimento sobre os limites da aprendizagem profunda
Primeiro, LeCun esclareceu que, o que geralmente é chamado de limitações do aprendizado profundo é um limite do aprendizado supervisionado.
- Leia tambem: Skymizer anuncia placa PCIe de IA capaz de rodar LLMs gigantes localmente sem clusters de GPUs
O aprendizado supervisionado é a categoria de algoritmos de aprendizado de máquina que requerem dados de treinamento anotados.
Por exemplo, se você deseja criar um modelo de classificação de imagens, você deve treiná-lo em um grande número de imagens que foram rotuladas com a classe apropriada.
"Aprendizado profundo não é aprendizado supervisionado, não são apenas redes neurais, é basicamente a ideia de construir um sistema montando módulos parametrizados em um gráfico de computação", disse LeCun em seu discurso na AAAI. Você não programa diretamente o sistema, você define a arquitetura e ajusta esses parâmetros.
LeCun ainda acrescenta que o aprendizado profundo pode ser aplicado a diferentes paradigmas de aprendizado, incluindo aprendizado supervisionado, aprendizado por reforço e aprendizado não supervisionado ou auto supervisionado.
Existem algumas razões para a confusão que envolve aprendizado profundo e aprendizado supervisionado. No momento, a maioria dos algoritmos de aprendizado profundo que chegaram às aplicações práticas são baseados em modelos de aprendizado supervisionado, o que diz muito sobre as deficiências atuais dos sistemas de IA.
Classificadores de imagem, sistemas de reconhecimento facial, sistemas de reconhecimento de fala e muitos dos outros aplicativos de IA que usamos todos os dias foram treinados em milhões de exemplos rotulados.
O aprendizado por reforço e o aprendizado não supervisionado, as outras categorias de algoritmos de aprendizado, encontraram até agora aplicações muito limitadas.
Onde está o aprendizado profundo hoje?
O aprendizado profundo supervisionado nos deu muitas aplicações muito úteis, especialmente em áreas como visão computacional e algumas áreas do processamento de linguagem natural.
Além disso, esta tecnologia está desempenhando um papel cada vez mais importante em aplicativos sensíveis, como a detecção de câncer.
Ela também está provando ser extremamente útil em áreas onde a escala do problema está além dos esforços humanos, como com algumas ressalvas, revisando a enorme quantidade de conteúdo sendo postado nas mídias sociais todos os dias.
"Sem a aprendizagem profunda no Facebook, Instagram, YouTube etc., essas empresas desmoronam", disse LeCun.
"Elas são completamente construídos em torno dela", acrescentou.
Mas como mencionado, o aprendizado supervisionado é aplicável apenas onde há dados de qualidade suficientes e os dados podem capturar a totalidade dos cenários possíveis.
Assim que os modelos de aprendizado profundo treinados enfrentam novos exemplos que diferem dos exemplos de treinamento, eles começam a se comportar de maneiras imprevisíveis.
Em alguns casos, mostrar um objeto de um ângulo ligeiramente diferente pode ser suficiente para confundir uma rede neural e confundi-la com outra coisa.

O aprendizado por reforço profundo mostrou resultados notáveis em jogos e simulações. Nos últimos anos, o aprendizado por reforço conquistou muitos jogos que antes eram considerados fora dos limites da inteligência artificial.
Os programas de IA já dizimaram os campeões mundiais humanos em StarCraft 2, Dota e no antigo jogo de tabuleiro chinês GO. Mas a maneira como esses programas de IA aprendem a resolver problemas é drasticamente diferente da dos humanos.
Basicamente, um agente de aprendizado por reforço começa com uma folha em branco e é fornecido apenas com um conjunto básico de ações que ele pode executar em seu ambiente.
A IA é deixada por conta própria para aprender por tentativa e erro como gerar mais recompensas. Por exemplo, ganhar mais jogos.
- Leia tambem: Xbox encerra Copilot no console e diz que IA da Microsoft "não combina" com os planos da marca
Esse modelo funciona quando o espaço do problema é simples e você tem energia computacional suficiente para executar o maior número possível de sessões de tentativa e erro.
Na maioria dos casos, os agentes de aprendizado por reforço levam uma quantidade insana de sessões para dominar os jogos, o que aumenta o consumo de recursos.
Os enormes custos limitaram a pesquisa de aprendizado por reforço aos laboratórios de pesquisa pertencentes ou financiados por empresas ricas em tecnologia.
Os sistemas de aprendizado por reforço são muito ruins no aprendizado por transferência, um bot que joga StarCraft 2 no nível de mestre principal precisa ser treinado do zero se quiser jogar o Warcraft 3.
Mesmo pequenas alterações no ambiente do jogo StarCraft podem prejudicar imensamente o desempenho da IA. Por outro lado, os humanos são muito bons em extrair conceitos abstratos de um jogo e transferi-los para outro jogo.
O aprendizado por reforço realmente mostra seus limites quando deseja aprender a resolver problemas do mundo real que não podem ser simulados com precisão, "e se você quiser treinar um carro para dirigir sozinho?
É muito difícil simular isso com precisão", disse LeCun, acrescentando que, se quiséssemos fazer isso na vida real", teríamos que destruir muitos carros".
Diferentemente dos ambientes simulados, a vida real não permite executar experimentos em avanço rápido, e experimentos paralelos, quando possível, resultariam em custos ainda maiores.
Os três desafios da aprendizagem profunda
LeCun divide os desafios do aprendizado profundo em três áreas.
- Primeiro, precisamos desenvolver sistemas de IA que aprendam com menos amostras ou menos ensaios. "Minha sugestão é usar o aprendizado não supervisionado, ou prefiro chamá-lo de aprendizado auto supervisionado, porque os algoritmos que usamos são realmente semelhantes ao aprendizado supervisionado, que basicamente é aprender a preencher os espaços em branco", diz LeCun.
"Basicamente, é a ideia de aprender a representar o mundo antes de aprender uma tarefa, é isso que bebês e animais fazem, corremos pelo mundo, aprendemos como funciona antes de aprender qualquer tarefa, uma vez que temos boas representações do mundo, aprender uma tarefa exige poucas tentativas e poucas amostras."Os bebês desenvolvem conceitos de gravidade, dimensões e persistência de objetos nos primeiros meses após o nascimento, embora exista um debate sobre o quanto dessas capacidades são conectadas ao cérebro e quanto delas são aprendidas, o certo é que desenvolvemos muitas de nossas habilidades simplesmente observando o mundo.
- O segundo desafio é criar sistemas de aprendizado profundo que possam raciocinar. Os atuais sistemas de aprendizado profundo são notoriamente ruins em raciocínio e abstração, e é por isso que eles precisam de grandes quantidades de dados para aprender tarefas simples.
"A questão é: como vamos além da computação feed-forward e do sistema 1? Como tornamos o raciocínio compatível com a aprendizagem baseada em gradiente? Como tornamos o raciocínio diferenciável? Esse é o resultado final", disse LeCun.O sistema 1 é o tipo de tarefa de aprendizado que não requer pensamento ativo, como navegar em uma área conhecida ou fazer pequenos cálculos. O sistema 2 é o tipo de pensamento mais ativo, que requer raciocínio. A inteligência artificial simbólica, a abordagem clássica da IA, provou ser muito melhor em raciocínio e abstração.
Mas LeCun não sugere retornar à IA simbólica ou a sistemas híbridos de inteligência artificial, como outros cientistas sugeriram.
Sua visão para o futuro da IA está muito mais alinhada com a de Yoshua Bengio, outro pioneiro em aprendizado profundo, que introduziu o conceito de aprendizado profundo do sistema 2 no NeurIPS 2019 e o discutiu ainda mais na AAAI 2020.
LeCun, no entanto, admitiu que "Ninguém tem uma resposta completamente boa" para qual abordagem permitirá que os sistemas de aprendizado profundo raciocinem.
- O terceiro desafio é criar sistemas de aprendizado profundo que possa inclinar e planejar sequências de ações complexas e decompor tarefas em subtarefas.
Os sistemas de aprendizado profundo são bons em fornecer soluções de ponta a ponta para os problemas, mas muito ruins em dividi-los em etapas específicas interpretáveis e modificáveis.Houve avanços na criação de sistemas de IA baseados na aprendizagem que podem decompor imagens, fala e texto, as redes de cápsulas, inventadas por Geoffry Hinton, abordam alguns desses desafios.
Mas aprender a raciocinar sobre tarefas complexas está além da IA de hoje. "Não temos ideia de como fazer isso", admite LeCun.
Aprendizagem auto supervisionada

A idéia por trás do aprendizado auto supervisionado é desenvolver um sistema de aprendizado profundo que possa aprender a preencher os espaços em branco.
"Você mostra ao sistema uma parte da entrada, um texto, um vídeo e até uma imagem, suprime uma parte, mascara e treina uma rede neural ou sua classe ou modelo favorito para prever a parte que está faltando. Pode ser o futuro de um vídeo ou as palavras que faltam em um texto", disse LeCun.
O mais próximo que temos dos sistemas de aprendizado auto supervisionado é o Transformers, uma arquitetura que se mostrou muito bem-sucedida no processamento de linguagem natural, os Transformers não requerem dados rotulados.
Eles são treinados em grandes corpora de textos não estruturados, como artigos da Wikipedia, e eles provaram ser muito melhores do que seus antecessores na geração de texto, no diálogo e na resposta a perguntas, mas eles ainda estão muito longe de realmente entender a linguagem humana.
Os Transformers se tornaram muito populares e são a tecnologia subjacente a quase todos os modelos de linguagem de ponta, incluindo o BERT do Google, o RoBERTa do Facebook, o GPT2 da OpenAI e o Chatbot do Google Meena.
Recentemente, os pesquisadores de IA provaram que os Transformers podem realizar a integração e resolver equações diferenciais, problemas que requerem manipulação de símbolos.
Isso pode ser uma dica de que a evolução dos Transformers pode permitir que as redes neurais superem as tarefas de reconhecimento de padrões e aproximação estatística.
Até agora, os Transformers provaram sua eficiência com dados discretos, como palavras e símbolos matemáticos.
"É fácil treinar um sistema como esse, porque existe alguma incerteza sobre qual palavra pode estar faltando, mas podemos representá-la com um vetor gigante de probabilidades em todo o dicionário e, portanto, não é um problema", disse LeCun.
Mas o sucesso dos Transformers não foi transferido para o domínio dos dados visuais.
"É muito mais difícil representar incertezas e previsões em imagens e vídeos do que em texto porque não é discreto. Podemos produzir distribuições em todas as palavras do dicionário, não sabemos como representar distribuições em todos os quadros de vídeo possíveis", disse LeCun.
Para cada segmento de vídeo, existem inúmeros futuros possíveis, isso torna muito difícil para um sistema de IA prever um único resultado.
Digamos que nos próximos quadros em um vídeo, a rede neural acabe calculando a média dos resultados possíveis, o que resulta em resultados borrados.
"Esse é o principal problema técnico que temos que resolver se queremos aplicar o aprendizado auto supervisionado a uma ampla variedade de modalidades como o vídeo", disse LeCun.
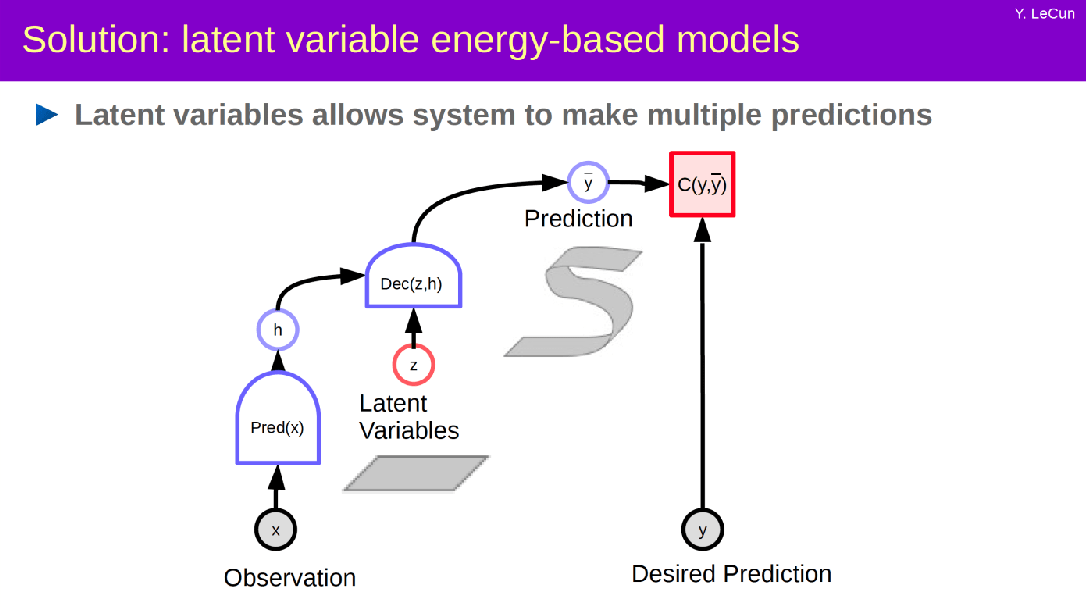
O método preferido de LeCun para abordar o aprendizado supervisionado é o que ele chama de "modelos baseados em energia variável latente".
A ideia principal é introduzir uma variável latente Z que calcula a compatibilidade entre uma variável X, o quadro atual de um vídeo, e uma previsão Y no futuro do vídeo selecionando o resultado com a melhor pontuação de compatibilidade.
Em seu discurso, LeCun detalha ainda mais os modelos baseados em energia e outras abordagens para o aprendizado auto supervisionado.
O futuro da aprendizagem profunda não é supervisionado
"Acho que o aprendizado auto supervisionado é o futuro, isso é o que permitirá aos nossos sistemas de IA, o sistema de aprendizado profundo, avançar para o próximo nível. Talvez aprender bastante conhecimento de fundo sobre o mundo por observação, para que algum tipo de bom senso possa surgir", disse LeCun em seu discurso na Conferência AAAI.
Um dos principais benefícios do aprendizado auto supervisionado é o imenso ganho na quantidade de informações geradas pela IA. No aprendizado por reforço, o treinamento do sistema de IA é realizado no nível escalar.
O modelo recebe um único valor numérico como recompensa ou punição por suas ações, no aprendizado supervisionado, o sistema de IA prevê uma categoria ou um valor numérico para cada entrada.
No aprendizado auto supervisionado, a saída melhora para uma imagem inteira ou um conjunto de imagens.
"É muito mais informação, para aprender a mesma quantidade de conhecimento sobre o mundo, você precisará de menos amostras", disse LeCun.
Ainda precisamos descobrir como o problema da incerteza funciona, mas quando a solução surgir, teremos desbloqueado um componente essencial do futuro da IA.
"Se a inteligência artificial é um bolo, o aprendizado auto supervisionado é a maior parte do bolo", disse LeCun.
"A próxima revolução na IA não será supervisionada nem puramente reforçada", acrescentou.
Via: AAAI







