
A AMD acaba de lançar seu primeiro modelo de linguagem, o AMD-135M, um modelo descrito como "pequeno" e voltado para otimizar processos de inteligência artificial (IA).
Esse modelo se diferencia dos demais por utilizar a Decodificação Especulativa, uma técnica para melhorar a eficiência e velocidade de geração de tokens em sistemas de IA.
O AMD-135M chega como o primeiro modelo de linguagem pequena (SLM) da AMD, parte da família Llama. Ele foi treinado em aceleradores AMD Instinct™ MI250, utilizando um volume de 670 bilhões de tokens de dados gerais.
O modelo foi subdividido em dois: o AMD-Llama-135M e o AMD-Llama-135M-code, cada um com uma finalidade específica.
O primeiro é um modelo geral, enquanto o segundo foi ajustado para lidar com códigos, sendo treinado com 20 bilhões de tokens adicionais voltados para dados de programação.
Esse processo de treinamento durou apenas seis dias, usando quatro nós do MI250, o que mostra a alta capacidade de processamento dos equipamentos da AMD.
Além disso, ele é de código aberto e a AMD também disponibiliza os dados e os pesos desse modelo para que desenvolvedores possam replicá-lo e contribuir no treinamento de outros modelos de linguagem, tanto pequenos (SLMs) quanto grandes (LLMs).
O diferencial: Decodificação Especulativa
Tradicionalmente, grandes modelos de linguagem (LLMs) utilizam uma abordagem autorregressiva na inferência, o que significa que cada passagem gera apenas um token.
Esse método, apesar de ser bem eficiente, pode ser lento e consumir muitos recursos, já que limita a eficiência de acesso à memória.
É aí que entra a Decodificação Especulativa, o grande trunfo do AMD-135M. Essa técnica permite que o modelo de IA produza da AMD diversos tokens de uma só vez, reduzindo drasticamente o tempo de processamento.
Funciona da seguinte maneira: um modelo menor, conhecido como "modelo de rascunho", gera um conjunto de tokens candidatos.
Esses tokens são, então, validados pelo modelo principal, o que possibilita um processo muito mais ágil, sem sacrificar a precisão.
Isso tudo se traduz em uma otimização do uso de memória e melhora a velocidade de inferência em várias ordens de magnitude.
Desempenho do AMD-135M
Nos testes realizados pela AMD, o AMD-Llama-135M foi utilizado como modelo de rascunho para o CodeLlama-7b, a fim de avaliar o desempenho com e sem decodificação especulativa.
Os resultados mostraram uma aceleração significativa em diversos hardwares da empresa, como o acelerador Instinct MI250, o Ryzen AI CPU e o Ryzen AI NPU.
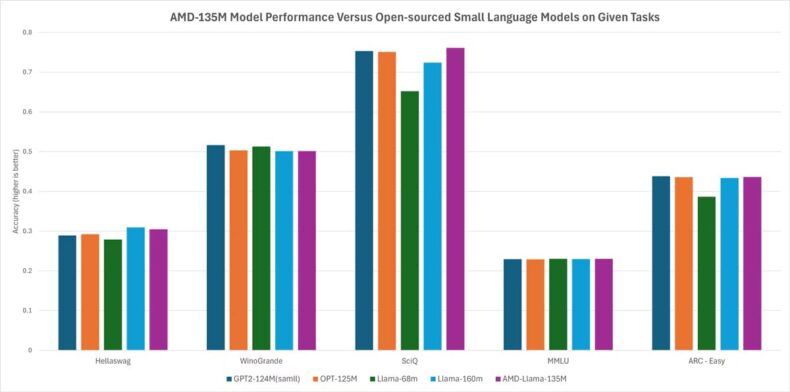
Essas melhorias reforçam o potencial da decodificação especulativa para otimizar a velocidade e eficiência, tanto em data centers quanto em PCs focados em IA.
Essa combinação de treinamento, inferência e decodificação especulativa, integrada nas plataformas da AMD, estabelece um novo patamar no desenvolvimento de SLMs e LLMs, trazendo soluções mais rápidas e eficazes para a crescente demanda por IA em diferentes áreas.
AMD busca tornar a IA mais acessível
Ao lançar o AMD-135M, a AMD segue uma abordagem de IA aberta, inclusiva e ética. A empresa acredita que o progresso na área de IA deve ser amplamente compartilhado e acessível, o que é evidenciado pela abertura de seu código para desenvolvedores.
Além disso, esse movimento ajuda a garantir que os desafios associados à IA sejam enfrentados de maneira mais colaborativa, buscando maximizar os benefícios dessa tecnologia para a sociedade como um todo.







